For a long time I have used the bash on a daily basis. It has become such a trustworthy companion
that I virtually cannot do any work on a windows box anymore. But even using bash every day I
regularly come across ways of solving particular tasks that I did not really know about.
To keep track of such solutions, I try to keep my cheat-sheets up to date with what I found and
learned during the year. In tradition with 2011 and 2012 I again took a look at the git-log and
compiled 10 of the things that I learned or used a lot in the shell.
This year is different though since I decided to go into a little more detail about some of the
items where I felt it was instructional. I also included a small table of contents, mainly ‘cause I
tend to come back to those tips myself a lot and wanted a quicker way to find the item in question.
1> awk
awk is probably the most powerful unix tool I encountered so far. It’s actually a whole
programming language, not just a tool. I tend to stay clear of the more complicated uses but for
some small output processing it’s just invaluable.
The basic structure of awk statements is always the same, first you list a pattern to match,
second the action you want awk to perform:
awk [condition] [{action}]In the action it is possible to refer to different parts of the current input record. If awk is
fed some lines of text, it will process each line that satisfy the condition and dissect it into
parts. That is often helpful if only some parts of the output are wanted.
Dependent include files
One of the situations where this was just the right tool for me was trying to find recursively all dependent header files of a C-file. The compiler (clang in my case) can greatly help here since it has to know about the headers it needs. And it comes with an option to list this information:
-H Show header includes and nesting depthI found this option is less picky than -M. Using it, the information about included header files
will be displayed along with lots of other stuff that is unwanted in this case. awk can be used to
filter the results down to the relevant lines and further extract the file names from those lines.
In the example below
- all error messages are filtered out (
2>/dev/null, see redirects section) - clang is used to list the recursive include tree (
cpp -H [include-paths] [C/C++-file]) awkfirst filters all lines with header information (/^#.*\.h\"$/)- and extracts the header name (
{print $3}) tris used to get rid of the""quotation-marks- finally all duplicates are removed by using
sortanduniq
kernel(master) > 2>/dev/null cpp -H -Iinclude crypto/fcrypt.c \ | awk '/^#.*\.h\"$/ {print $3}' | tr -d '""' | sort | uniq include/asm-generic/atomic-long.h include/linux/atomic.h include/linux/bitmap.h include/linux/compiler.h include/linux/completion.h include/linux/cpumask.h include/linux/crypto.h ...
2> ls
Plain old ls is probably my most used command. But ls can do some nice tricks, too. Using the
-S flag, ls will sort the files by size. Combined with -h it produces a very readable result:
kernel(master) > ls -lSh | head -5
total 6352
-rw-r--r-- 1 muellero staff 236K Jun 6 2013 sched.c
-rw-r--r-- 1 muellero staff 139K Jun 6 2013 cgroup.c
-rw-r--r-- 1 muellero staff 130K Jun 6 2013 sched_fair.c
-rw-r--r-- 1 muellero staff 104K Jun 6 2013 workqueue.c
Often very helpful is also to only include the most recent files. -t will sort files by the date they were modified the last time.
ls -l -tIn a directory with lots of files it’s sometimes practical to only list the directories. The -d
option makes sure directories are listed as plain files and not searched recursively. Since all
directories end in / this can be used to list only those.
ls -d */Of course the opposite is also achievable, this one only lists the files. For this you can use -p
which will write a slash (“/”) after each filename if that file is a directory.
ls -p | ack -v /This one can nicely be combined with some awk magic to count the file-types by extensions in a
directory:
kernel(master) > ls -p | ack -v / | awk -F . '{print $NF}' | sort | uniq -c
1 Makefile
112 c
1 freezer
17 h
...
Here awk was used to split at the “.” and print the last part (which is the extension).
3> find
Again a classic. After ls for sure an all-time favorite. Can also be combined with an action.
Here, find first seeks out all symbolic links in the current directory and deletes them.
find . -type l -deleteThis only works for reasonably recent versions of find. For older versions the following syntax should works as well:
find . -type l -exec rm {} \;4> ack
Ever since I found ack-grep I most of the time us it as a replacement for grep. The developers
claim that it is ”…designed as a replacement for 99% of the uses of grep…” but to be honest, I
never found that a case where it failed me. Out of the box it just works and produces beautifully
highlighted results. But more importantly, it adds some nice features that I really grew to like.
And it’s quite fast. For most of my usecases faster then grep since it only searches whitelisted
files by default. This guy here has put together a pretty good comparison with some performance
tests.
Limit to certain File-Types
One very handy feature is the ability to narrow the search down to certain file types. By default
ack already knows about countless file types (can be checked with ack --help=types). Limiting
the searched files dramatically reduces the search time.
Here is an example of searching all C and C++ source files for a pattern and include 2 lines of
context before (-B) and after (-A) the found match.
kernel(master) > ack --type=cpp probability -B 2 -A 2 drivers/net/ethernet/sun/cassini.h 875- 876-/* probabilities for random early drop (RED) thresholds on a FIFO threshold 877: * basis. probability should increase when the FIFO level increases. control 878: * packets are never dropped and not counted in stats. probability programmed 879- * on a 12.5% granularity. e.g., 0x1 = 1/8 packets dropped. 880- * DEFAULT: 0x00000000
Highlighter
A lesser common usecase for ack is the passthru mode. In this mode ack does not limit the
output to the matching positions but spills out the whole input, highlighting the search-matches in
the process. This practically makes ack a formidable highlighting tool.
kernel(master) > ls | ack -i mutex --passthru ... lockdep_internals.h lockdep_proc.c lockdep_states.h module.c mutex-debug.c mutex-debug.h mutex.c mutex.h notifier.c nsproxy.c ...
5> rename
Mass renaming in the shell is usually done with some form of loop, e.g.
for i in *.zip ; do mv "$i" "${i%.zip}`date +%Y`.zip"; doneHere a substitution operation is used to cut of the extension part which is then replaced with the
year + the extension. The same thing using rename would look like this:
rename -X -a `date +%Y` *.zipThis is using the -a transform that appends some string to each filename.
rename part of filename
Using for loops can become complicated pretty soon, and for those cases rename is a pretty good
alternative. Say when you have a bunch of files that contain the string “Aug” in their name but want
to replace it with “08”. The by far easiest way I have found to accomplish stuff like this is to use
the rename command.
rename 's/Aug/08/' *.*rename takes modification rules and applies them to the files that match a pattern (if given,
otherwise it expects a list of filenames on stdin). The beauty of this utility is that it comes
with support for lot’s of common cases out of the box. For example, if files contain spaces or other
unwanted characters, there is the option to sanitize them using -z.
tmp > ls a b c_.tif tmp > rename -n -z * 'a b c_.tif' would be renamed to 'a_b_c_.tif'
Here the option -n is applied as well, resulting in a dry run without any actual modifications.
The -z option will replace all sequences of whitespaces or control characters with a single “_”,
replace every shell meta-character with “_” and remove spaces and underscores from left and right
end.
The result is almost as desired… just the trailing “_” is still annoying. The sanitize
command did not remove it. That’s because the file extension is the last part of the filename. But
I’d really like to sanitize the name without the extension. Turns out rename has a very handy
feature that allows to save and remove the last extension before any modifications and slab it on
again afterwards.
tmp > rename -n -X -z *
'a b c_.tif' would be renamed to 'a_b_c.tif'
put files in folders according to their endings
This is something I use more and more often.
rename -p -X -e '$_ = "$EXT/$_" if @EXT' *This will move all files into folders that have the same name as their extension. The -p is needed
to make sure directories are created if needed. The -X chopes of the extension and saves it into
the $EXT variable. -e will evaluate the following expression, in this case evaluate to a path
consisting of the stored extension together with the filename if an extension exists.
p→ creates directories if neededX→ chop of extension and append after the operatione→ evaluate perl expression$EXT→ A string containing the accumulated extensions saved by “-X” switches, without a leading dot@EXT→ An array containing the accumulated extensions saved by “-X” switches, from right to left, without any dots
Note that rename is not available on all systems by default and you might need to install it, e.g.
brew install rename on OSX.
6> Redirects
For some shell commands I always have to consult my notes or google. Mostly that is ‘cause I haven’t taken the time to really understand the underlying concept. Redirects are a perfect example: simple enough to just use them so most people don’t worry about their mechanics.
Everything in UNIX is a file
Data streams and peripherals are treated as files, just like ordinary files. Each gets a file-descriptor assigned that can then be used to access the stream. A file-descriptor is an integer associated with a network connection, a pipe or a real file, amongst other things. When executing a command, it will mainly work with 3 different file-descriptors/files:
- 0 ≘ stdin
- 1 ≘ stdout
- 2 ≘ stderr
Redirecting Output
For redirecting output you use “>” (the output redirection operator).
Probably my most widely used redirect is to write to a file instead of stdout. The example will
write to a .gitignore file, possibly creating it in the process if it doesn’t already exist.
echo temp > .gitignoreSlightly more useful is often to use the same redirect but append to a file rather than to overwrite it:
echo temp >> .gitignoreSuch basic redirects are valid for the whole line and are a short form for specifying the target
file descriptor explicitly (>> ≡ 1>>). They can also appear before the command:
1>> .gitignore echo temp # redirect stdout and append to .gitignore
Of course redirects are not limited to redirecting to a file. Have you ever tried to redirect the
output of a command to a file but there were still some messages displayed on the terminal that did
not get redirected? This is a quite common case where stderr needs to be redirected to stdout so
that all error messages are sent to stdout:
myCommand 2>&1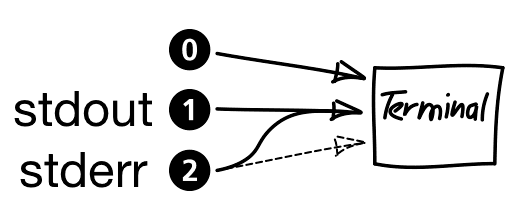
The & is similar to the address operator in C/C++ and is used to name a file-descriptor. So
2>&1 tells the shell that we want file-descriptor (2) (stderr) to point to the same file as
file-descriptor (1) (stdout). This works with any file-descriptor, not just (2) and
(1): x>&y will point file-descriptor x to where y is pointing to.
Using this knowledge, we can swap where 2 file-descritors point with a technique similar to pointer swapping in C:
myCommand 3>&1 1>&2 2>&3 3>&-A temporary file-descriptor (3) is used as a temp. It will first capture the file pointed by
stdout which is then be redirected to where stderr points to. As a last step stderr is now
pointed to where stdout pointed originally and (3) is closed as it no longer is needed.

Order of Redirects
A fact that often causes considerable confusion is that the order of the redirects matters. Actually not to hard to remember once you picture the file-descriptors as pointers to files. If we for example try to capture stdout and stderr in a file, one might be tempted to use something like this:
myCommand 2>&1 >> my_log_file.txt
But this does not work as expected. Here, stderr is first pointed at the same file as stdout
(i.e. the terminal). Then we redirect stdout away from the terminal to a file.
If both stdout and stderr should be captured in a file, we need to reverse the order of the redirects:
myCommand >>my_log_file.txt 2>&1 # capture everything in a file
Armed with an understanding how redirects work, it’s now quite simple to understand the following example:
Only use stderr output
Redirect stderr to where stdout points to and then stdout to /dev/null (dump it). The output
can then further be processed, here we pipe it to grep for something.
myCommand 2>&1 >/dev/null | grep 'foo'
Redirecting Input
Similar to how we can modify stdout and stderr, stdin can also be replaced as an input to a
program using the input redirection operator “<”.
myCommand < inputFile # same as cat inputFile | myCommandCombining input and output redirection is also possible for one command:
myCommand < inputFile > outFile7> Subshells
Quite often I want to download some file using wget and put it into my download folder. At the
same time I don’t want to loose the context (current working directory).
One way to deal with this is to cd into the download directory, issue the wget command, and use
a quick cd - to return from where you started. Lately my preferred way is to use a subshell.
tmp > (cd ~/downloads; wget http://www.example.com/abc.tar.gz)
A subshell is a child process of the process the shell is running in with access to the environment
of it’s parent process. But any changes to the environment done in this child-process does not
propagate to the parent. Thus we can change the directory, set or unset environment variables and so
on.
Another nice example is to remove the http_proxy from the environment when temporarily not needed:
tmp > (unset http_proxy; wget http://www.example.com/abc.tar.gz)
Bonus Example
I just found another very nice usage of subshells on the discussion board of vimcasts. Barton Chittenden showed how to avoid the use of temporary files for using vimdiff using process substitution in bash:
tmp > vimdiff <(sort file1) <(sort file2)
8> Tee
Sometimes there is more then one consumer for some command output. This is what tee can be used
for. It takes as an input the output of some other command using stdin and duplicates it, feeding
the two streams to a file-descriptor and stdout.

After taking a look at redirects and subshells here is a neat
commandlinefu-example of how tee can be used to split a pipe into multiple streams for one or
more subshells to work it.
tmp > echo "tee can split a pipe in two" | tee >(rev) >(tr ' ' '_') tee can split a pipe in two owt ni epip a tilps nac eet tee_can_split_a_pipe_in_two
Copy directory multiple time
To copy a directory containing everything without temporary files and preserving ownership,
permissions, and timestamps is often done with tar.
tar cf - . | (cd targetDir && tar xfp -)tar will create an archive containing everything in the current directory. The “-“ is used to
write to stdout instead of a file. The output is then piped into a subshells to
change into the target directory and extract the everything.
Copying everything twice can be accomplished using tee:
tar cf - . | tee >(cd targetDir && tar xfp -) | (cd targetDir2 && tar xfp -)Here tee will duplicate stdin and feed it to a process substitution and to stdout, which in turn is then piped to the subshell.
9> Zips & Archives
Compressed archives are a brilliant way to exchange files… everything is bundled together, in general takes up way less space and can even be password protected. Inspecting or unpacking them usually involves creating temporary directories or files. But there are some handy ways to acoid such intermediate products.
view zipfiles
Often you just need to peek inside without actually extracting anything. zipinfo is a nice little utility that does just that.
tmp > zipinfo tmp.zip
Archive: tmp.zip 20400 bytes 2 files
-rw-r--r-- 3.0 unx 19960 bx defN 14-Nov-12 11:05 colordiff-1.0.13.tar.gz
-rw-r--r-- 3.0 unx 72 bx stor 14-Nov-12 11:06 colordiff-1.0.13.tar.gz.sig
2 files, 20032 bytes uncompressed, 20022 bytes compressed: 0.0%
But of course unzip can also perform the task. The -t option tests an archive file, listing it’s content in the process:
tmp > unzip -t tmp.zip
Archive: tmp.zip
testing: colordiff-1.0.13.tar.gz OK
testing: colordiff-1.0.13.tar.gz.sig OK
No errors detected in compressed data of tmp.zip.
A third and my prefered option is to use unzip with it’s -l option (lists the content of the archive file).
tmp > unzip -l tmp.zip
Archive: tmp.zip
Length Date Time Name
-------- ---- ---- ----
19960 11-14-12 11:05 colordiff-1.0.13.tar.gz
72 11-14-12 11:06 colordiff-1.0.13.tar.gz.sig
-------- -------
20032 2 files
Unpacking
Even upacking does not necessarily involve spilling the zipped files out to disk. The content of a zip-archive can be extracted and fed to a pipe so that it becomes usable by another process.
tmp > echo "text me" > test.txt tmp > zip storage test.txt; rm test.txt adding: test.txt (stored 0%) tmp > ls storage.zip tmp > unzip -p storage.zip | rev em txet tmp > ls storage.zip
Here I created a sample zip archive and extracted it to feed the content to rev without creating any files in the process.
Inspecting tar Archives
Most of the archives dealt with under Linux are compressed tar files, so here is how you list their content.
First, for a gzipped file (ending in *.tar.gz or *.tgz):
tar -ztvf file.tar.gzAnd finally for the bzip2 formats:
tar -jtvf file.tar.bz2t→ list contentsv→ verbose, display detailed informationz→ filter through gzip (for *.gz fils)j→ filter through bzip2 (for *.bz2 fils)f→ filename
10> Base Conversion
Even though printf in C/C++ offers great many pitfalls, I still like to use it often despite
having access to C++ iostreams. Bash also supports a form of printf that can easily be used to do
some basic number conversions.
convert decimal to hex/octal
Just as in C, the bash printf can easily print numerical values in different formats:
tmp > printf "%#x\n" 100 0x64 tmp > printf "%#o\n" 100 0144
The #-character is the alternative format modifier and is responsible for prepending the “0x”
for hexadecimal values and a leading zero for octal values.
convert hex to decimal
tmp > printf "%d\n" 0x64
100
Print a conversion table from decimal to hex
A nice example I found in the Bash Hackers Wiki is to print out a conversion table:
tmp > for ((x=0; x <= 127; x++)); do printf '%3d | 0x%02x\n' "$x" "$x"; done
0 | 0x00
1 | 0x01
2 | 0x02
3 | 0x03
...
Done for 2013
Ok, this was my bash feature list of the year. By no means am I an expert for the features described. If you see something that is incorrect or might otherwise be completed more elegantly I’d be glad to hear it!
Photo: Todd Quackenbush